排查一些模糊的东西
- 1.客户反馈系统慢
- 2.系统假死了
- 3.前面两点的排查后最终还是要落到某个点的优化(但是如何找到这个点?
遇到这类问题要做的事
- 1.出问题首先把系统dump文件导出来(切记重启不是第一位)
1234 pid
jmap -dump:format=b,file=/var/logs/heap.hprof 1234
- 2.有一点要注意导dump也不是万能的,也可能是别的系统影响了公用的第三方组件(例如跑不掉的数据库)。我之前就遇到过两个系统的库在一台服务器上的不同空间其中一个库主业务是稽核跑数据的,业务老是反应系统慢后来偶然间优化了那个稽核的业务那边反应慢的问题也少了。
- 3.像系统因为内存不够挂掉的提前做配置项(内存溢出的时候自动导出dump
- 4.有了有问题的dump我们可以结合代码针对运行的线程,并再测试环境复现或者定位一些问题了。
- 5.慢的问题需要一个一个去看了比较哪个影响的比较大;
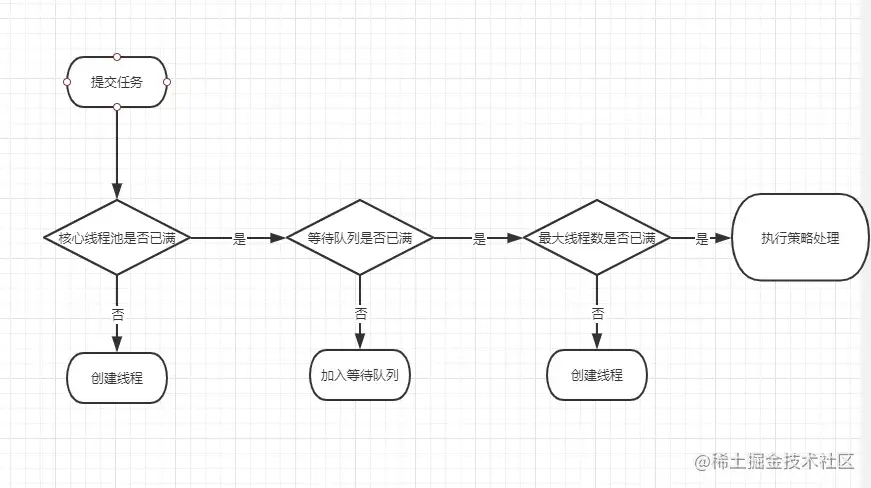
- 6.假死如何看系统,系统处理不过来了,为什么处理不过来了?单个系统支持的请求就那么多(线程池内能用的线程都被占用了排队等待的又不断涌入你说能不挂吗,重点关注下共性的卡顿点了)
问题如何发现
- 1.提前防范只能监控告警(一般的监控系统)。
- 2.最近发现了一个轻量级的监控工具HertzBeat(提供了很多监控有容器、库、中间件,网络,云,java有对sprigboot的......),因为够轻也有缺点了看情况了。(tomcat是通过jmx协议进行的,springboot根据暴漏的的一些指标http进行的)
- 3.一切都是线程池,dynamictp提供线程池级别的监控。
- 4.因为我没做过互联网项目不知道是否每天有复盘排查慢的地方进行针对优化的
- 5.一般情况下库的问题比较直接些。数据库和、数据库中间件都有慢sql记录的隔一段时间优化下就可以了。
- 6.提前防范问题我们可以通过accesslog进行了,通过一定时间的访问记录我们可以知道哪些具体的业务是慢的,针对这个业务我们可以再通过arthas进行准确定位和修复。
